Evaluating AI Search Providers

I evaluated several AI search providers, including the new OpenAI Web Search API, to compare them against my current provider Perplexity.
Introduction
AI-powered search is revolutionizing how developers access information and build intelligent applications. Unlike traditional search engines that rely solely on keyword matching and link analysis, AI-powered search understands context, can synthesize information from multiple sources, and provides more relevant results for complex queries.
With the growing number of providers in this space, choosing the right one for your specific needs can significantly impact both your user experience and your budget.
As a developer building Token Radar, a site that provides information about various cryptocurrencies, I needed to find the most effective AI search solution for generating accurate and up-to-date crypto-related content.
TL;DR
Here's a quick summary of my findings:
| Provider | Best For | Cost/1k | Key Advantage | Main Drawback |
|---|---|---|---|---|
| Openperplex GPT-4o-Mini | General Use | $12 | Best quality/cost ratio | |
| Perplexity Sonar Pro | Premium Needs | $14.65 | Most accurate results | Higher cost |
| Linkup Standard | Budget Option | $5 | Great value | No search filters |
| OpenAI Web Search, Exa | Not Recommended | $5-40 | Good documentation | Expensive, lower quality |
For Token Radar's specific use case, I decided to use Linkup Standard for most tasks and Openperplex GPT-4o-Mini for questions where up-to-date information is crucial.
I will keep Perplexity Sonar Pro as a backup.
Key Players in the Evaluation
The evaluation included several providers:
- Perplexity: Sonar and Sonar Pro Models [link]
- OpenAI: Web Search API [link]
- Linkup: Standard and Deep Models [link]
- Openperplex: Various Models [link]
- Others: Exa, Critique Labs, and Jina
Price Ranges
The pricing landscape for AI search providers varies dramatically, ranging from as low as $5 to as high as $2,000 per 1,000 requests.
Here's how the major providers stack up:
| Provider (different models) | Cost (USD per 1,000 requests) |
|---|---|
| Perplexity | $5-15 |
| OpenAI | $25-40 |
| Linkup | $5-50 |
| Openperplex | $12-96 |
| Exa | $5-15 |
| Critique Labs | $0.125 |
| Jina | $2,000 |
Test Methodology
I used three different types of questions, that all have a practical use case in my app Token Radar, to evaluate the providers:
- FAQ Questions: Questions about specific tokens to generate automated FAQ content for token pages.
- Preview Questions: Questions about tokens that are not yet released or may never be released.
- Price Increase Questions: Questions about tokens that have had significant price movements.
To test the providers, I created a simple Python script for each provider and each question type. The script outputs the results as markdown files for later analysis.
Rating System Explained
For each test, I evaluated responses using two methods:
- AI Rating (1-3 scale): I used Claude Sonnet 3.7 to analyze responses based on accuracy, relevance, and completeness. A score of 1 indicates poor quality, while 3 represents excellent quality.
- Manual Rating (1-3 scale): I personally reviewed each response, considering factors like factual accuracy, usefulness for the intended purpose, and clarity of information.
I also calculated the cost per 1000 requests for each provider and considered this in my final rankings.
Results Breakdown
Preview Questions
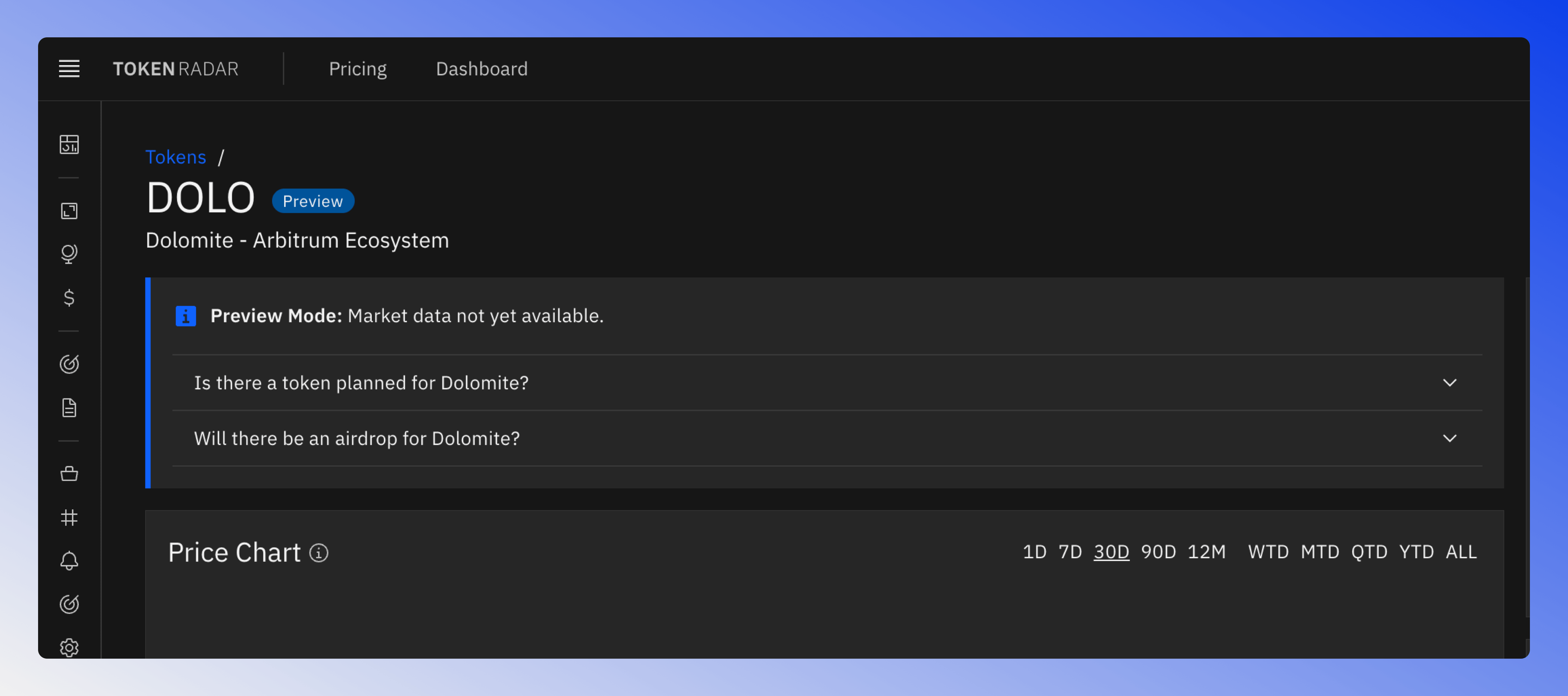
On Token Radar, I also list tokens that are not yet released or may never be released. For these tokens, I ask two key questions:
- Will there actually be a token released?
- Is there an airdrop that users can participate in?
These questions can be challenging for search providers since many of these newer tokens are very niche and not well documented.
Checkout the Dolomite token page for a live example.
Key findings from preview question testing:
- Linkup Standard led with perfect AI scores and great value ($5/1k)
- OpenAI and Perplexity Pro tied for accuracy but at higher costs ($10-35/1k)
- Openperplex models performed well but were less consistent
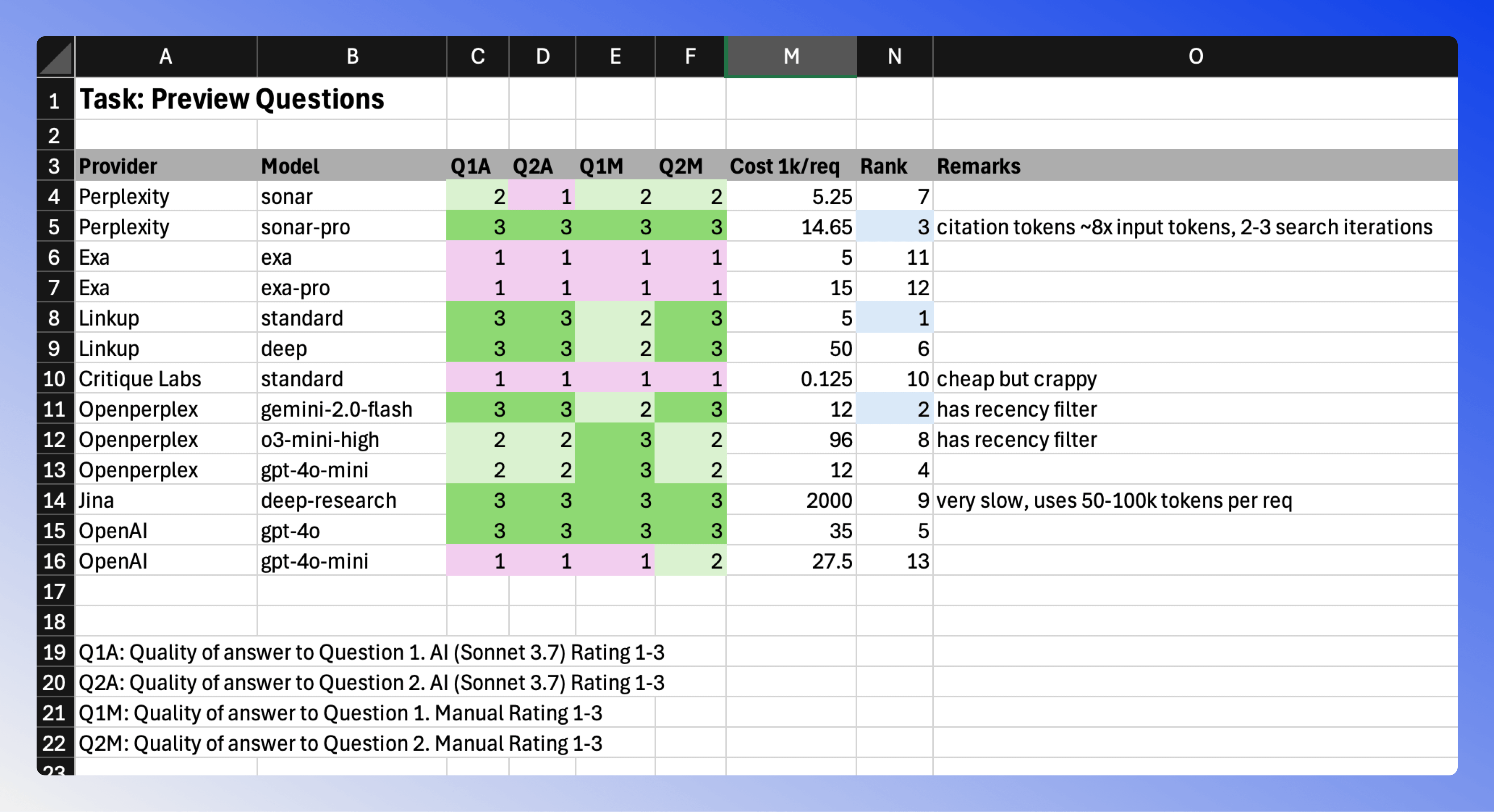
Jina's deep-research model showed perfect scores but came with significant drawbacks:
- Very slow processing
- Very Expensive at $2000 per 1k requests
Note: I eliminated models from further testing that significantly underperformed or where to expensive before moving on to other question types.
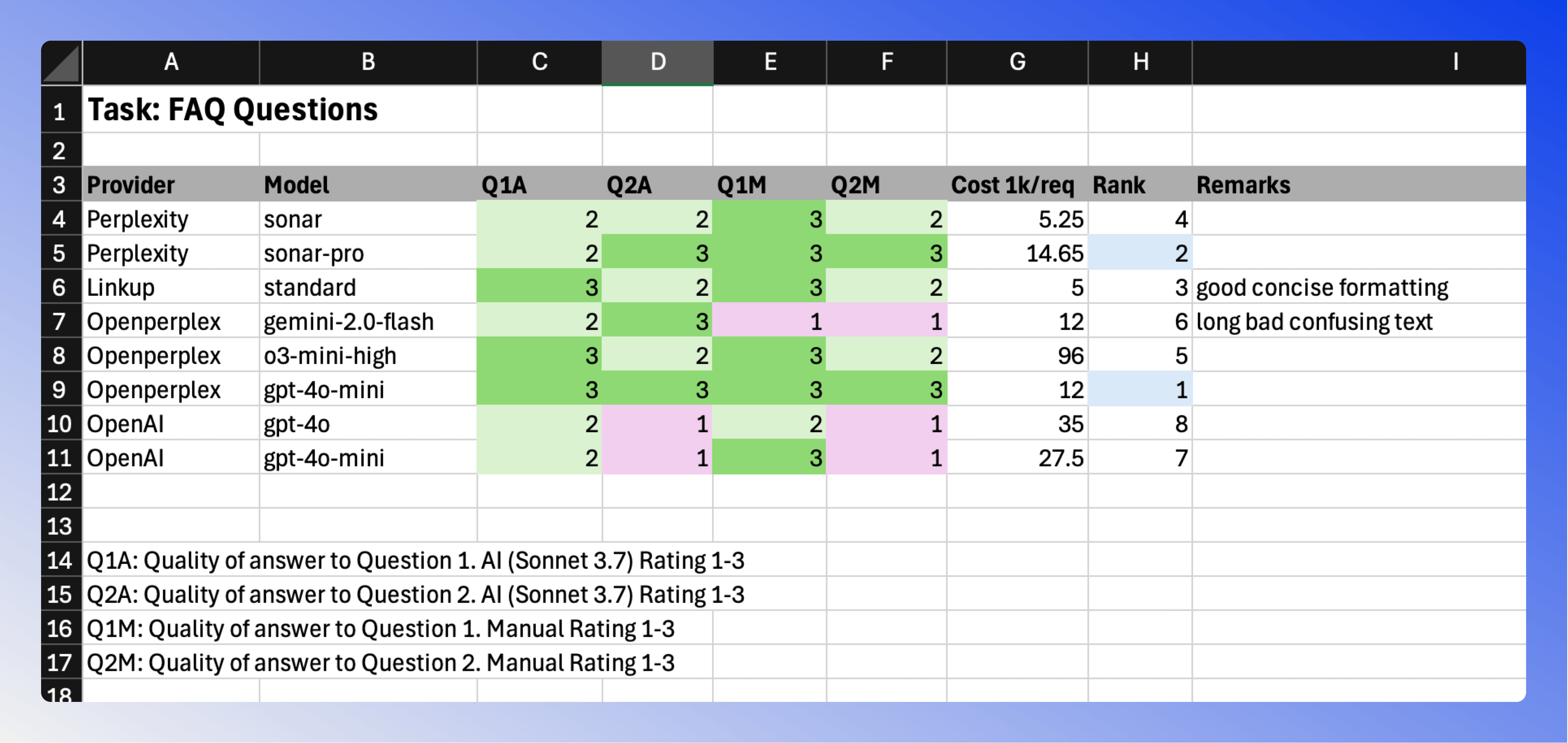
FAQ Questions
For this test, I asked various questions about specific tokens to generate automated FAQ content for token pages. The questions covered topics like the use case and technical details that users commonly want to know about a token.
Checkout the Bitcoin token page for a live example.
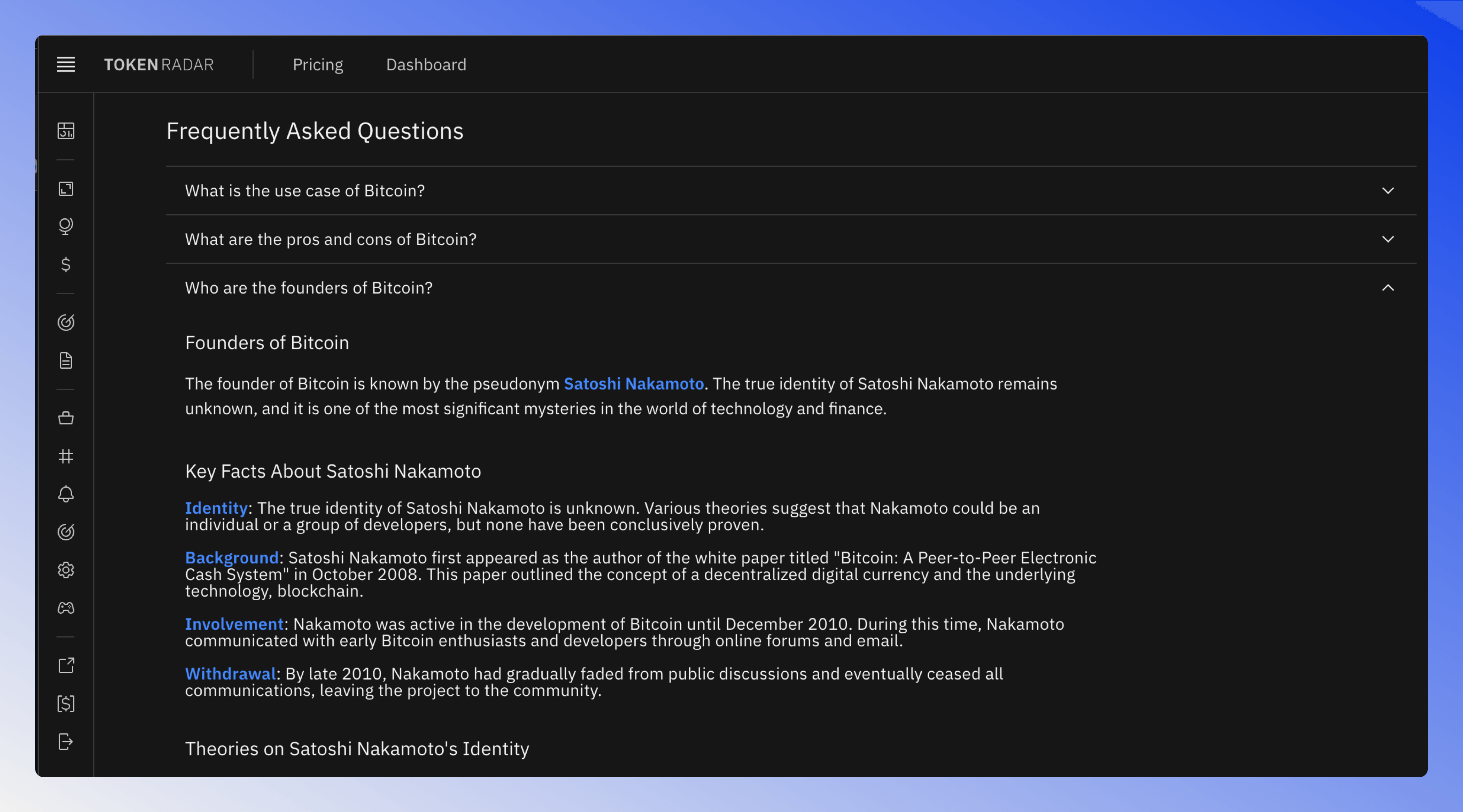
The standout performer was Openperplex's GPT-4o-Mini model, achieving consistent high scores (3/3) across both AI and manual evaluations. Perplexity Sonar Pro also performed well, though at a higher cost point ($14.65 per 1k requests).
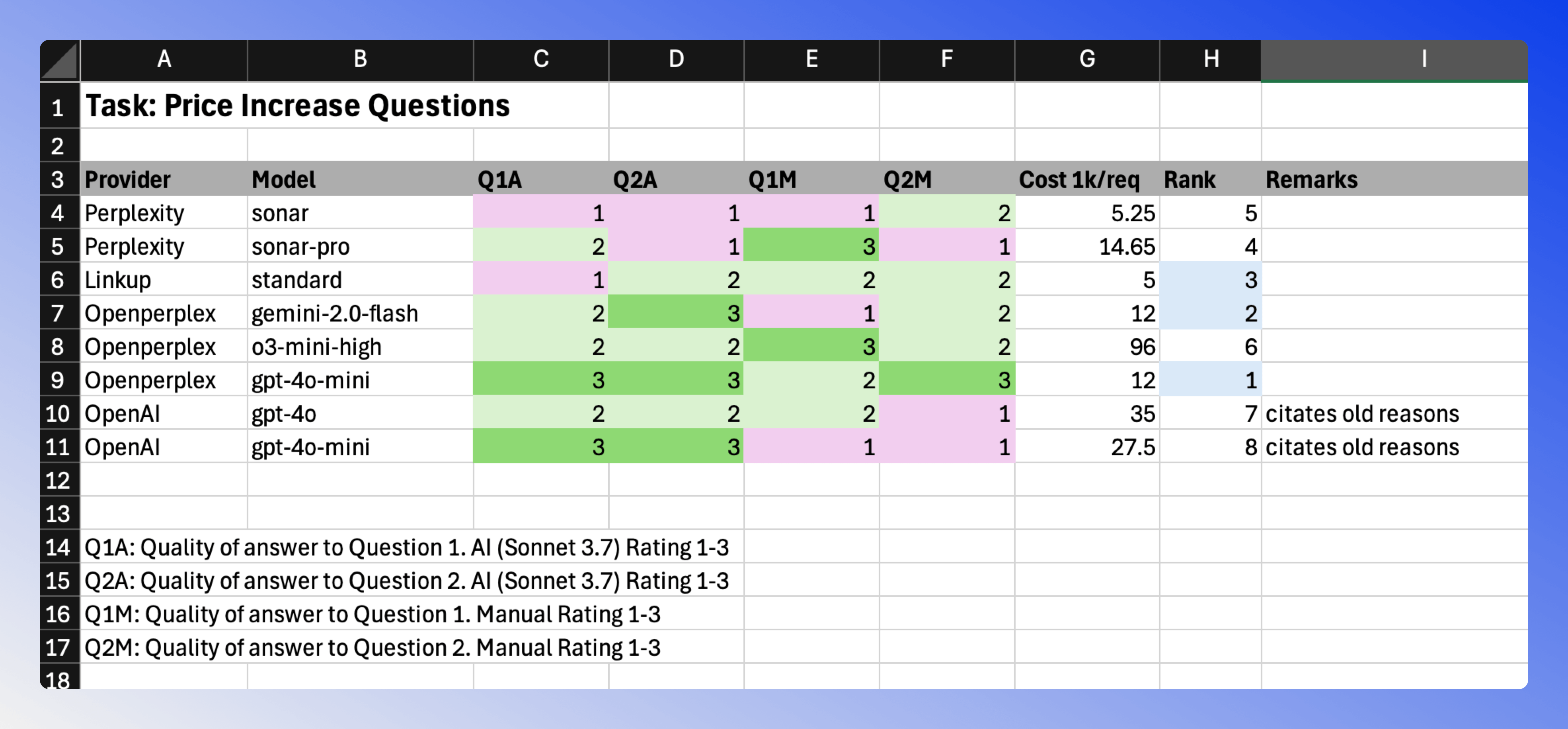
Price Increase Questions
For significant token price movements, I want to understand the underlying causes. This type of query presents a unique challenge because only recent events are relevant - historical price movements from months or years ago don't help explain current volatility.
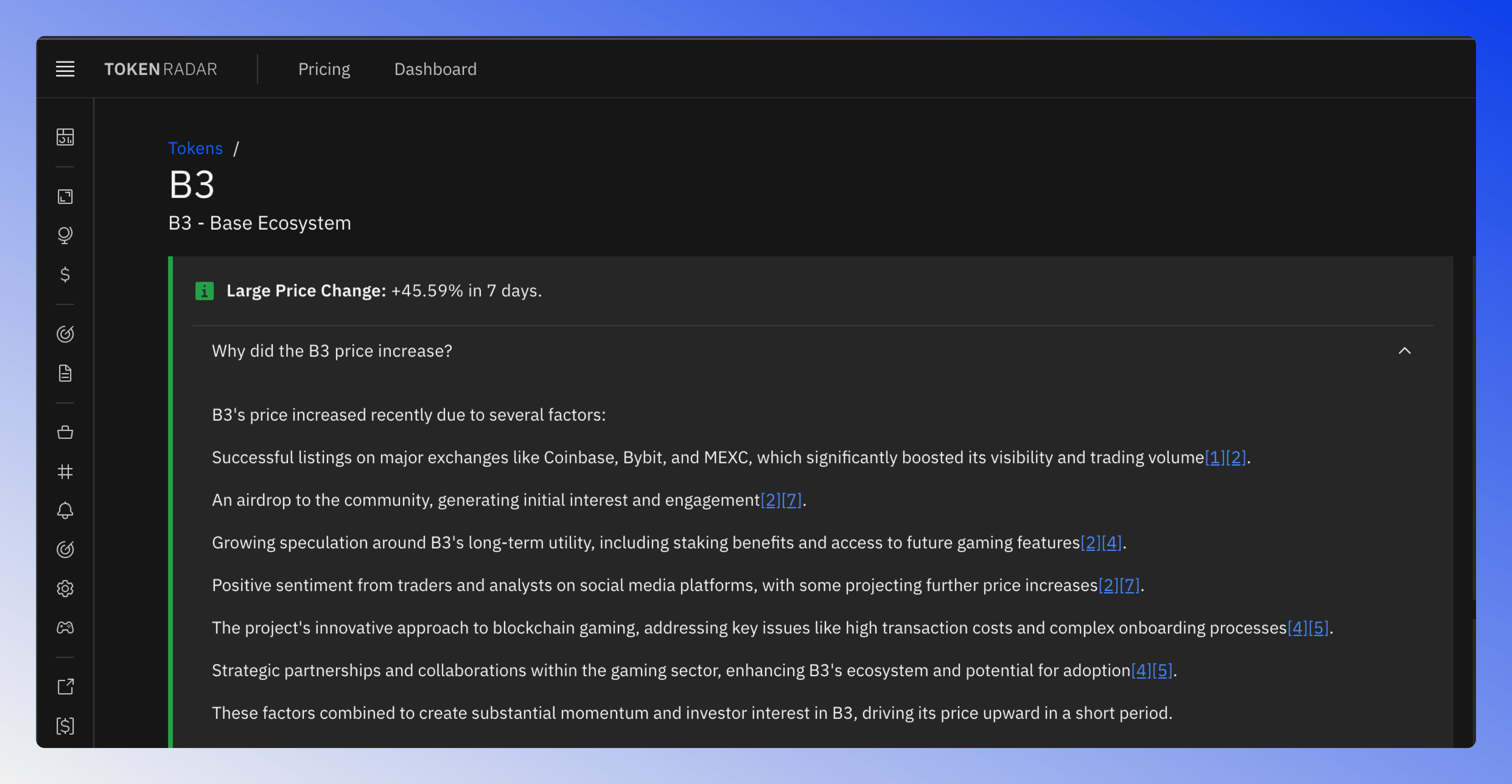
The final test revealed:
- Openperplex's GPT-4o-Mini and Linkup Standard maintained their strong performance
- Most providers struggled with consistency in this category, showing varying performance between AI and manual ratings
- Perplexity and Openperplex were the only providers that provided filters to only show recent events, giving them an advantage in this category
Conclusions
Based on the comprehensive evaluation:
Best Overall Value: Linkup Standard
- Good performance
- Reasonable pricing ($5 per 1k requests)
- Good balance of quality and cost
Best Performance: Openperplex with GPT-4o-Mini
- Top rankings in multiple categories
- Competitive pricing ($12 per 1k requests)
- Consistent quality across different question types
Premium Option: Perplexity Sonar Pro
- More expensive but with reliable performance
- Good for cases requiring premium quality and the most up-to-date information
- Strong recency filters for time-sensitive queries
Final Thoughts�
For Token Radar, I've implemented a hybrid approach:
- I will use Linkup Standard for the FAQ and Preview questions, because it's the most cost effective and performs well.
- For the Price Increase questions, I will use Openperplex GPT-4o-Mini because it provides up-to-date information.
- I will also implement strategies to minimize costs while maintaining freshness of information.
Remember that your specific use case might require different trade-offs between cost, performance, and specific features like recency filters. I recommend running your own small-scale tests with your specific use cases before committing to a provider.